Raft Lite: An Easy-to-understand Implementation of Raft Consensus Algorithm
Raft Lite is a simple and easy-to-understand implementation of the Raft consensus algorithm. In this post, I will explain the internal implementation of Raft Lite. Please find the complete implementation of Raft Lite in the Raft Lite repository if you are interested.
Consensus algorithm and total order broadcast
State machine replication (SMR) is a fundamental problem in distributed systems. The problem is as follows: suppose we have a set of nodes, each of which maintains a state machine. The state machine can be any arbitrary state machine, such as a key-value pair storage system, a database, or a file system. The state machine can transition to the next state by executing an instruction. The problem is how we can ensure that all nodes execute the same sequence of instructions, so that all nodes can reach the same state.
Consensus algorithms are designed to solve the SMR problem. In a consensus algorithm, each node can propose a value, with only one value being ultimately chosen. Through multiple iterations of this process, the nodes can reach a consensus on a sequence of values. The sequence of values can be used as the sequence of instructions to be executed by the state machine.
A formally equivalent form of the consensus algorithm is total order broadcast, which I believe is easier to understand for most developers. It functions as a library, just like a network protocol does. The following figure shows the idea. We assume that the network is point-to-point, and messages may encounter loss, disorder, or delays. Such a network could be built using TCP, UDP, or any other suitable protocol.
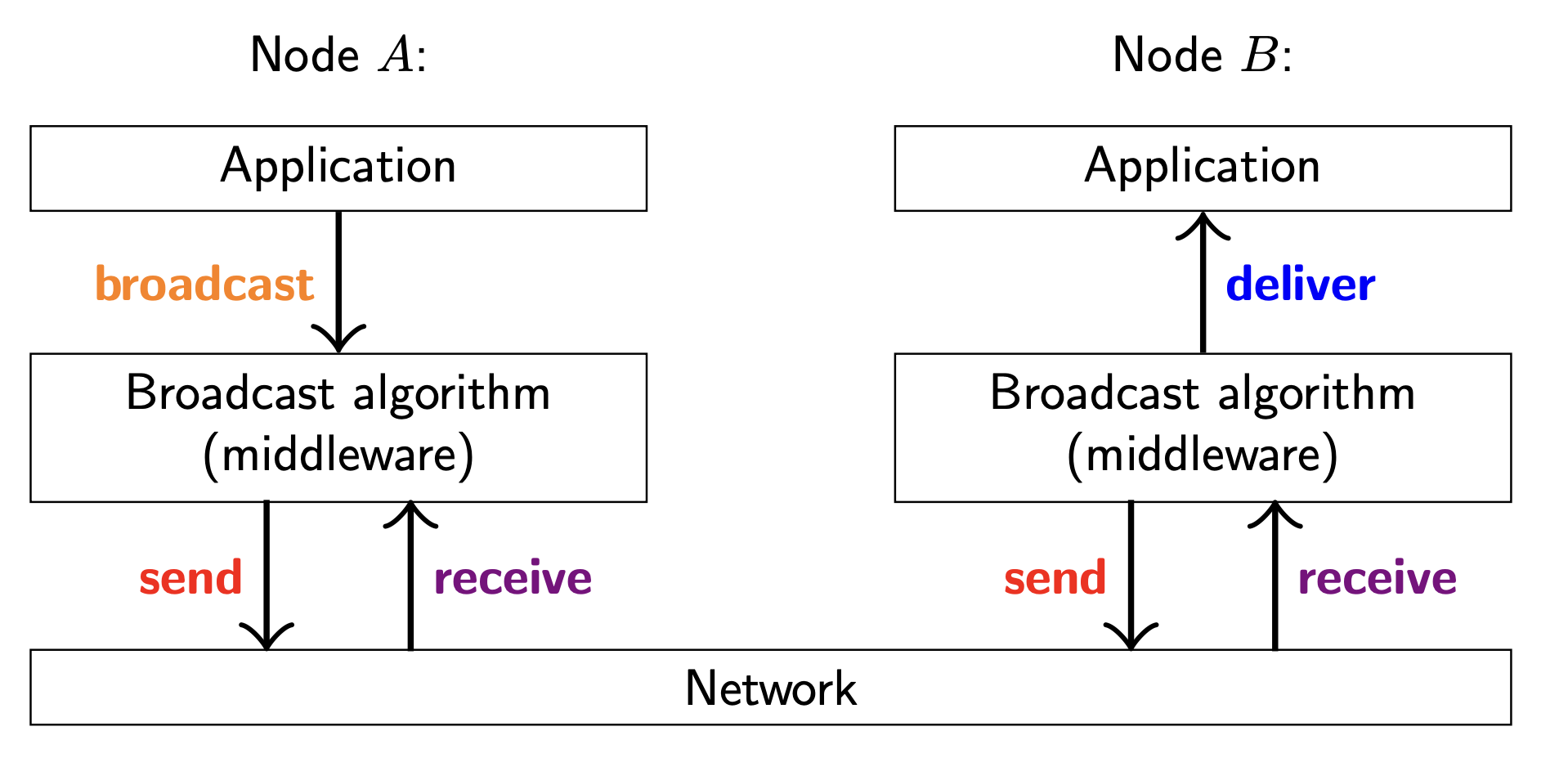
Figure from Distributed System Course.
Although you can use raw TCP connections to achieve broadcast, the total order broadcast library gives stronger guarantees. The library ensures that the arrival order of messages is consistent across all nodes. For example, if node A and node B broadcasts messages m1 and m2 respectively, then the arrival order of m1 and m2 on one node must be the same as the arrival order of m1 and m2 on any other node.
Using the total order broadcast library, we can solve the SMR problem as follows:
-
Each node maintains a state machine.
-
Whenever the application layer wants to execute an instruction, it broadcasts the instruction to all nodes using the total order broadcast library.
-
When a node receives an instruction, it executes the instruction and updates its state machine.
That is to say, the total order broadcast library ensures that all nodes deliver the same sequence of messages. Therefore, all nodes can execute the same sequence of instructions, and reach the same state.
Please note that “deliver” is different from “receive”. The total order broadcast library might receive a message, but not deliver it to the application layer immediately. The library will wait until all the messages before it are delivered to the application layer.
While Raft is explained in the form of consensus algorithm in the original paper, I’ll explain and implement Raft Lite in the form of total order broadcast, which presumably facilitates a more intuitive understanding.
API of Raft Lite
As mentioned above, Raft Lite is a total order broadcast library. The API of Raft Lite is as follows:
raft := new_raft_instance(id, peers);
(broadcast_channel, delivery_channel) := raft.run();
And you can use the channels to build a state machine:
on request to execute an instruction do
send the instruction to broadcast_channel
end on
on receiving an instruction from delivery_channel do
execute the instruction on the state machine
end on
Internal overview of Raft Lite
While Raft paper is much clearer than Paxos paper, translating it into usable code remains challenging. The complexity arises due to the paper’s heavy reliance on natural language rather than pseudocode to articulate the algorithm. Furthermore, apart from the AppendEntries and RequestVote RPCs, algorithmic descriptions are dispersed across different sections and figures in the paper. A reader needs to combine those algorithm snippets carefully to get a complete Raft algorithm.
Therefore, Raft Lite uses a event loop to describe the Raft algorithm, since the event loop is a more concrete and intuitive way to describe the algorithm. The events include:
enum Event {
ElectionTimeout,
ReplicationTimeout,
VoteRequest,
VoteResponse,
LogRequest,
LogResponse,
Broadcast,
}
And the event loop looks like this:
loop {
let event = wait_for_event();
switch event {
case ElectionTimeout:
start_election();
case ReplicationTimeout:
handle_replicate_log();
case VoteRequest:
handle_vote_request();
case VoteResponse:
handle_vote_response();
case LogRequest:
handle_log_request();
case LogResponse:
handle_log_response();
case Broadcast:
handle_broadcast();
}
}
In the following, I will give pseudo-code for Raft’s processing of each event, as well as explanations of these pseudo-codes. The rust implementation of Raft Lite is also given. If you want to see the complete implementation, please refer to the Raft Lite repository.
Most of the pseudocode for Raft Lite comes from my master’s supervisor Martin Kleppmann’s Distributed Systems Course . I modified it slightly to make it easier to understand and implement.
The basic idea of Raft
The basic idea of Raft is as follows:
-
A leader is elected among all nodes. The leader is responsible for receiving broadcast requests from all the nodes, and sorting them into a log.
-
The leader sends the log to all nodes. The nodes will deliver the log entries to application in the same order.
If we can find an election algorithm that guarantees there is only one leader from the beginning to the end of the system, then the implementation of Raft will be very simple - just the description in the previous paragraph will suffice.
However, a leader may fail or be disconnected from the network. In this case, a new leader must be elected. Therefore, the election algorithm cannot guarantee a unique leader throughout the system’s operation. Raft’s election algorithm offers a weaker assurance: at any given time, there exists at most one leader, or possibly none.
“At any given time” is the key phrase here. In distributed systems, we usually do not use physical clocks to describe time given their tendency to drift. Instead, logical clocks are used. Raft uses a logical clock known as “term” represented as an integer where higher values denote later time. The Raft election algorithm can guarantee that there exists at most one leader in any term.
Even if we’ve found an election algorithm that guarantees at most one leader in any term, the log replication process won’t be as straightforward as outlined earlier. This is because the transition from one leader to another may result in different delivery orders of log entries on different nodes.
For example, suppose node A is the leader in term 1, and node B is the leader in term 2. Let’s assume node A broadcasts message m1 in term 1, all the nodes except node B receive and deliver m1. Then node B becomes the leader in term 2, and broadcasts message m2. In this case, the node B will deliver m2 without delivering m1, while all other nodes has already delivered m1 before m2.
To solve this problem, Raft’s log replication algorithm guarantees that the log entry is delivered only if it is acknowledged by a majority of the nodes, and only the node receiving the majority of the votes can become the leader. A node can vote another one only if the log of the candidate is more up-to-date than its own log. Therefore, the intersection of the two majorities guarantees that the a node must deliver the most up-to-date log entries before it become a leader. Don’t worry if you don’t understand this paragraph, we’ll give a detailed explanation later.
In the following sections, we’ll explain how Raft implements the election algorithm and log replication algorithm.
Initialization
on initialisation do
currentTerm := 0;
votedFor := null;
currentRole := follower;
currentLeader := null;
votesReceived := {};
log := [];
commitLength := 0
sentLength := [];
ackedLength := [];
end on
Lines 2 to 6 are related to elections, while lines 8 to 11 are related to message broadcasting.
These variables consistently maintain the following semantics throughout the algorithm:
log: all log entries of the node. These log entries may or may not have been delivered to the application layer. Log entries across different nodes might vary temporarily, but they will eventually converge to the same state.commitLength:log[0..commitLength - 1]are the message that has been delivered to the application layer, andlog[commitLength..]are the message yet to be delivered to the application layer. It’s important to note that uncommitted log entries might be removed, whereas committed entries are retained permanently.ackedLength: node k acknowledge thelog[0..ackedLength[k]-1]has been received.sentLength: the leader assumes thatlog[0..sentLength[k] - 1]of node k matches the leader’s log entries.current_term: the logical clock of the node.votes_received: votes received during the ongoing term.
Rust implementation in Raft Lite:
struct NodeState {
id: u64, // id of the node
current_term: u64, // 0
voted_for: Option<u64>, // None
current_role: Role, // Follower
current_leader: Option<u64>, // None
votes_received: HashSet<u64>, // {}
log: Vec<LogEntry>, // []
commit_length: u64, // 0
sent_length: Vec<u64>, // []
acked_length: Vec<u64>, // []
}
ElectionTimeout
Each node has a election timer, which is reset when receving the heartbeat from its leader.
When the Election Timer expires, the follower will transition to the role of “candidate”. Following this transition, it will proceed to send voting requests to all nodes.
on election timeout do
currentTerm := currentTerm + 1; // start election in a new term, since we need to guarantee that at most one leader exists in a term
if currentRole == Leader then
return; // do nothing if the node is already a leader
end if
currentRole := candidate; // become a candidate (not yet a leader)
votedFor := nodeId; // vote for self
votesReceived := {nodeId}; // currently, the node have one vote (the node itself)
lastTerm := 0 // this is a temporary value, denoting the term of the last log entry. we will explain it later
if log.length > 0 then
lastTerm := log[log.length − 1].term;
end if
msg := (VoteRequest, nodeId , currentTerm , log.length, lastTerm) // send vote request to all nodes
for each node in nodes:
send msg to node
start election timer // reset election timer, if the node does not receive a majority of votes within the election timeout, it will start a new election
end on
Rust implmenetation in Raft Lite:
fn start_election(&mut self) {
let state = &mut self.state;
if state.current_role == Role::Leader {
return;
}
let id = state.id;
state.current_term += 1;
state.voted_for = Some(id);
state.current_role = Role::Candidate;
state.votes_received.clear();
state.votes_received.insert(id);
let mut last_term = 0;
if state.log.len() > 0 {
last_term = state.log.last().unwrap().term;
}
let msg = VoteRequestArgs {
cid: id,
cterm: state.current_term,
clog_length: state.log.len() as u64,
clog_term: last_term,
};
for i in 0..self.config.peers.len() {
if i == id as usize {
continue;
}
self.runner.vote_request(i as u64, msg.clone());
}
}
VoteRequest
When node A receives a voting request from node B, it will perform the following steps:
- Check if the term of B is greater than or equal the current term of A. If not, A will reject the voting request, since voting for B might result in multiple leaders in B’s term.
- Check if the log of B is more or equal up-to-date than the log of A. If not, A will reject the voting request, since voting for B might result in log entries being lost.
- Check if A has already voted for another candidate in the current term. If so, A will reject the voting request, since voting for B might result in multiple leaders in the current term.
on receiving (VoteRequest,cId,cTerm,cLogLength,cLogTerm) at node nodeId do
if cTerm > currentTerm then
// If the term of the candidate is greater than the current term of the node, then the node should update its current term to the term of the candidate, and become a follower. This is because:
// 1. If the current node is a follower: it doesn't make sense to stay in the current term, since the leader may crash or disconnect.
// 2. If the current node is a leader: it might be disconnected from the network or crashed for a while. In this case, the current node should step down and become a follower.
currentTerm := cTerm;
currentRole := follower;
votedFor := null
end if
lastTerm := 0 // get the term of the last log entry
if log.length > 0 then
lastTerm := log[log.length − 1].term;
end if r
logOk := (cLogTerm > lastTerm) or (cLogTerm == lastTerm and cLogLength >= log.length)
// check if the log of the candidate is more up-to-date than the log of the node. logOk means the log of the candidate is more up-to-date than the log of the current node.
if cTerm == currentTerm and logOk and votedFor in {cId , null} then
// 1. If the term of the candidate is less than the current term of the node, then the node should reject the vote request.
// 2. If the log of the candidate is not more up-to-date than the log of the node, then the node should reject the vote request.
// 3. If the node has already voted for another candidate in the current term, then the node should reject the vote request.
votedFor := cId
send (VoteResponse, nodeId, currentTerm, true) to node cId
else
send (VoteResponse, nodeId, currentTerm, false) to node cId
// false means the node does not vote for the candidate, and the node will inform the candidate its current term. This is because the candidate may have a smaller term, and the node should make the candidate to update its term.
end if
end on
Rust implementation in Raft Lite:
fn handle_vote_request(&mut self, args: VoteRequestArgs) {
let state = &mut self.state;
if args.cterm > state.current_term {
state.current_term = args.cterm;
state.current_role = Role::Follower;
state.voted_for = None;
}
let mut last_term = 0;
if state.log.len() > 0 {
last_term = state.log.last().unwrap().term;
}
let log_ok = args.clog_term > last_term
|| (args.clog_term == last_term && args.clog_length >= state.log.len() as u64);
let mut granted = false;
if args.cterm == state.current_term
&& log_ok
&& (state.voted_for.is_none() || state.voted_for.unwrap() == args.cid)
{
state.voted_for = Some(args.cid);
granted = true;
}
let msg = VoteResponseArgs {
voter_id: state.id,
term: state.current_term,
granted,
};
self.runner.vote_response(args.cid, msg);
}
VoteResponse
Upon receiving voting responses, a node should check whether it has received a majority of votes. If so, it should transition to the role of leader. Otherwise, it should remain a candidate.
on receiving (VoteResponse, voterId, term, granted) at nodeId do
if currentRole == candidate and term == currentTerm and granted then
votesReceived.append(voterId)
// If the node is a candidate, and the term of the vote response is the same as the current term of the node, and the vote response is granted, then the node should add the voter to the list of votes received.
if |votesReceived| >= upper_bound[(|nodes| + 1)/2] then // if the node receives a majority of votes, then the node becomes a leader
currentRole := leader;
currentLeader := nodeId // the node becomes the leader of itself
for each follower in nodes \ {nodeId} do // for each follower, the node should send a heartbeat message to it
sentLength[follower] := log.length // the node assumes that the log of the follower is the same as its own log
ackedLength[follower] := 0 // the node does not receive any ack from the follower
ReplicateLog(nodeId,follower)
end for
end if
else if term > currentTerm then
// However, if the term of the vote response is greater than the current term of the node, then the node should update its current term to the term of the vote response, and become a follower. This is because the current node is already out of date, and it should step down and become a follower to avoid multiple leaders in the current term.
currentTerm := term
currentRole := follower
votedFor := null
reset election timer
end if
end on
Rust implementation in Raft Lite:
fn handle_vote_response(&mut self, args: VoteResponseArgs) {
let state = &mut self.state;
if state.current_role == Role::Candidate && args.term == state.current_term && args.granted
{
state.votes_received.insert(args.voter_id);
if state.votes_received.len() >= ((self.config.peers.len() + 1) + 1) / 2 {
state.current_role = Role::Leader;
state.current_leader = Some(state.id);
for i in 0..self.config.peers.len() {
if i == state.id as usize {
continue;
}
state.sent_length[i] = state.log.len() as u64;
state.acked_length[i] = 0;
}
self.handle_replicate_log();
}
} else if args.term > state.current_term {
state.current_term = args.term;
state.current_role = Role::Follower;
state.voted_for = None;
self.runner.election_timer_reset();
}
}
Broadcast
When the application layer triggers a broadcast, the leader will append the broadcast message to its log, and send the log entry to all followers. If the current node is not a leader, it will forward the broadcast message to the leader.
on request to broadcast msg at node nodeId do
if currentRole = leader then // if the node is a leader, then it can directly append the message to its log
append the record (msg : msg, term : currentTerm) to log
ackedLength[nodeId] := log.length // the node is synchronized with itself
for each follower in nodes \ {nodeId} do // synchronize the log with all followers
ReplicateLog(nodeId,follower)
end for
else if currentLeader != null then // if the node is not a leader, but it follows a leader, then it should forward the request to the leader
forward the request to currentLeader via a FIFO link
else
buffer the message until currentLeader != null // if the node is not a leader, and it does not follow a leader, then it should buffer the message until it follows a leader
end if
end on
Rust implementation in Raft Lite: please note that the buffer mechanism is handled by the runner, and is not shown here.
fn handle_broadcast(&mut self, payload: Vec<u8>) {
let state = &mut self.state;
if state.current_role == Role::Leader {
let entry = Arc::new(LogEntry {
term: state.current_term,
payload,
});
state.log.push(entry.clone());
let id = state.id as usize;
state.acked_length[id] = state.log.len() as u64;
self.handle_replicate_log();
} else {
self.runner.forward_broadcast(BroadcastArgs { payload });
}
}
ReplicationTimeout
When the replication timer expires, the leader will synchronize its log with all followers. The synchronization message also serves as a heartbeat message.
on replication timeout at node nodeId do
if currentRole = leader then
for each follower in nodes \ {nodeId} do
ReplicateLog(nodeId,follower)
end for
end if
end do
Rust implementation in Raft Lite:
fn handle_replicate_log(&mut self) {
let state = &self.state;
let runner = &mut self.runner;
if state.current_role != Role::Leader {
return;
}
let id = state.id;
for i in 0..self.config.peers.len() {
if i == id as usize {
continue;
}
Self::replicate_log(state, id, i as u64, runner);
}
}
ReplicateLog
ReplicateLog is a helper function that synchronizes the log of the leader with a follower.
The simplest way to synchronize the log is to send the entire log to the follower. However, this is inefficient. As mentioned earlier, the leader assumes that the log of the follower is the same as its own log when it becomes a leader. Therefore, the leader only needs to send the log entries that the follower does not have.
sentLength[follower] := log.length // the node assumes that the log of the follower is the same as its own log
The leader maintains a variable sentLength for each follower. sentLength[follower] denotes the length of the log that the leader believes the follower has. When the leader synchronizes the logs with the follower, it will send the log entries after sentLength[follower]. If the synchronization is failed, the leader will decrease sentLength[follower] by 1, and try again.
function ReplicateLog(leaderId, followerId)
prefixLen := sentLength[followerId] // we call the log entries that the leader believes are already replicated on the follower as prefix
suffix := [log[prefixLen], log[prefixLen + 1], ..., log[log.length − 1]] // only send the suffix of the log to the follower
prefixTerm := 0 // prefixTerm is the term of the last log entry in the prefix. We will explain it later.
if prefixLen > 0 then
prefixTerm := log[prefixLen − 1].term
end if
send (LogRequest,leaderId,currentTerm,prefixLen,prefixTerm,commitLength,suffix) to followerId
end function
Rust implementation in Raft Lite:
fn replicate_log(state: &NodeState, leader_id: u64, follower_id: u64, runner: &mut T) {
let prefix_len = state.sent_length[follower_id as usize];
let suffix = state.log[prefix_len as usize..].to_vec();
let mut prefix_term = 0;
if prefix_len > 0 {
prefix_term = state.log[prefix_len as usize - 1].term;
}
let msg = LogRequestArgs {
leader_id,
term: state.current_term,
prefix_len,
prefix_term,
leader_commit: state.commit_length,
suffix,
};
runner.log_request(follower_id, msg);
}
LogRequest
When a follower receives a synchronization message from the leader, it will perform the following steps:
-
The follower will check whether the log is consistent with the log entries that the leader believes the follower has. If not, the follower will reject the synchronization request.
-
If the log is consistent, the follower will append the suffix log entries to its own log.
-
The follower will check whether the leader has committed any log entries. If so, the follower will commit the log entries that the leader has committed.
To check whether the log is consistent, the follower will compare the term of the last log entry in the prefix with leader’s prefix_term. If they are not equal, the log is inconsistent. It is true due to a property of Raft: if two nodes have the same log term at the same index, then they have the same log entries at and before that index. Here we don’t give the proof of this property, but you can find it in the original paper.
on receiving (LogRequest,leaderId,term,prefixLen,prefixTerm, leaderCommit,suffix) at node nodeId do
if term > currentTerm then // if the term of the log request is greater than the current term of the node, then the node should become a follower of the leader
currentTerm := term;
votedFor := null
reset election timer
end if
if term == currentTerm then // if the term of the log request is the same as the current term of the node, then the node should become a follower of the leader (the current node might be a candidate)
currentRole := follower;
currentLeader := leaderId
end if
logOk := (log.length >= prefixLen) and (prefixLen == 0 or log[prefixLen − 1].term == prefixTerm) // if logOk is true, then the prefix of the leader is the same as the prefix of the follower. Otherwise, the leader should send the log request again.
if term = currentTerm and logOk then
AppendEntries(prefixLen , leaderCommit , suffix ) // update the log using suffix
ack := prefixLen + suffix.length // the node should notify the leader that it has received the log entries
send (LogResponse,nodeId,currentTerm,ack,true) to leaderId
else
send (LogResponse, nodeId, currentTerm, 0, false) to leaderId
end if
end on
Rust implementation in Raft Lite:
fn handle_log_request(&mut self, args: LogRequestArgs) {
let state = &mut self.state;
if args.term > state.current_term {
state.current_term = args.term;
state.voted_for = None;
self.runner.election_timer_reset();
}
if args.term == state.current_term {
state.current_role = Role::Follower;
state.current_leader = Some(args.leader_id);
self.runner.election_timer_reset();
}
let log_ok = (state.log.len() >= args.prefix_len as usize)
&& (args.prefix_len == 0
|| state.log[args.prefix_len as usize - 1].term == args.prefix_term);
let mut ack = 0;
let mut success = false;
let runner = &mut self.runner;
if args.term == state.current_term && log_ok {
Self::append_entries(
state,
args.prefix_len,
args.leader_commit,
args.suffix.clone(),
runner,
);
ack = args.prefix_len + args.suffix.len() as u64;
success = true;
}
let msg = LogResponseArgs {
follower: state.id,
term: state.current_term,
ack,
success,
};
self.runner.log_response(args.leader_id, msg);
}
AppendEntries
AppendEntries is a helper function that appends the suffix log entries to the log of the follower.
Here we check whether the follower has the same suffix log entries as the leader. If not, the follower will remove all the log entries after prefix from its log, and append the suffix log entries from leader to its log.
function AppendEntries(prefixLen,leaderCommit,suffix)
if suffix.length > 0 and log.length > prefixLen then // if the suffix of the leader is not empty, and the suffix of the follower is not empty
index := min(log.length, prefixLen + suffix.length) − 1 // get the index of the last log entry that can be compared
if log[index].term != suffix[index − prefixLen].term then // if they have different terms, then the suffix of the follower might be different from the suffix of the leader
log := [log [0], log [1], . . . , log [prefixLen − 1]] // remove the suffix of the follower
end if
end if
if prefixLen + suffix.length > log.length then // if the we can find log entries that can be appended
for i := log.length − prefixLen to suffix.length − 1 do
append suffix[i] to log // append the log entries to the log
end for
end if
if leaderCommit > commitLength then // logs[0..leaderCommit − 1] are acknowledged by the majority of nodes, so we can commit those log entries
for i := commitLength to leaderCommit − 1 do
deliver log[i].msg to the application
end for
commitLength := leaderCommit
end if
end function
Rust implementation in Raft Lite:
fn append_entries(
state: &mut NodeState,
prefix_len: u64,
leader_commit: u64,
suffix: Vec<Arc<LogEntry>>,
runner: &mut T,
) {
if suffix.len() > 0 && state.log.len() > prefix_len as usize {
let index = min(state.log.len(), prefix_len as usize + suffix.len()) - 1;
if state.log[index].term != suffix[index - prefix_len as usize].term {
state.log.truncate(prefix_len as usize);
}
}
if prefix_len as usize + suffix.len() > state.log.len() {
for i in state.log.len() - prefix_len as usize..suffix.len() {
state.log.push(suffix[i].clone());
}
}
if leader_commit > state.commit_length {
for i in state.commit_length..leader_commit {
runner.deliver_message(state.log[i as usize].payload.to_vec());
}
state.commit_length = leader_commit;
}
}
LogResponse
When the leader receives a log response from a follower, it will perform the following steps:
-
If the synchronization is successful, the leader will update
ackedLengthandsentLengthof the follower. -
If the synchronization is failed, the leader will decrease
sentLengthof the follower by 1, and try again.
on receiving (LogResponse,follower,term,ack,success) at nodeId do
if term == currentTerm and currentRole == leader then
if success = true and ack >= ackedLength[follower] then // if it is a successful response, and the follower might acknowledge some new log entries
sentLength[follower] := ack // update the sentLength of the follower
ackedLength[follower] := ack // update the ackedLength of the follower
CommitLogEntries()
else if sentLength[follower] > 0 then // if it is a failed response, and the leader should try a lower sentLength
sentLength[follower] := sentLength[follower] − 1
ReplicateLog(nodeId,follower) // try again
end if
else if term > currentTerm then // if the term of the log response is greater than the current term of the node, then the current node should step down and become a follower
currentTerm := term
currentRole := follower
votedFor := null
reset election timer
end if
end on
Rust implementation in Raft Lite:
fn handle_log_response(&mut self, args: LogResponseArgs) {
let state = &mut self.state;
let runner = &mut self.runner;
if args.term == state.current_term && state.current_role == Role::Leader {
if args.success && args.ack >= state.acked_length[args.follower as usize] {
state.sent_length[args.follower as usize] = args.ack;
state.acked_length[args.follower as usize] = args.ack;
Self::commit_log_entries(state, &self.config, runner);
} else if state.sent_length[args.follower as usize] > 0 {
state.sent_length[args.follower as usize] -= 1;
let id = state.id;
Self::replicate_log(state, id, args.follower, runner);
}
} else if args.term > state.current_term {
state.current_term = args.term;
state.current_role = Role::Follower;
state.voted_for = None;
self.runner.election_timer_reset();
}
}
CommitLogEntries
If the leader receives a majority of acknowledgements for a log entry, it will commit the log entry.
define acks(x) = |{n in nodes | ackedLength[n] >= x}| // acks(x) returns the number of nodes whose ackedLength is greater than or equal to x
function CommitLogEntries
minAcks := upper_bound(|nodes| + 1)/2) // minAcks is the minimum number of majority nodes.
ready := {len in {commitLength + 1, ... , log.length} | acks(len) >= minAcks } // ready is a set of integers, which contains the log indexes of the log entries that are acknowledged by the majority of nodes
if ready != {} and log[max(ready) − 1].term = currentTerm then // max(ready) is the largest log index in ready.
for i := commitLength to max(ready) − 1 do
deliver log[i].msg to the application
end for
commitLength := max(ready) // update commitLength
end if
end function
Rust implementation in Raft Lite:
fn commit_log_entries(state: &mut NodeState, config: &RaftConfig, runner: &mut T) {
let min_acks = ((config.peers.len() + 1) + 1) / 2;
let mut ready_max = 0;
// here is an optimization: we don't need to iterate through the whole log
for i in state.commit_length as usize + 1..state.log.len() + 1 {
if Self::acks(&state.acked_length, i as u64) >= min_acks as u64 {
ready_max = i;
}
}
if ready_max > 0 && state.log[ready_max - 1].term == state.current_term {
for i in state.commit_length as usize..ready_max {
runner.deliver_message(state.log[i].payload.to_vec());
}
state.commit_length = ready_max as u64;
}
}
fn acks(acked_length: &Vec<u64>, length: u64) -> u64 {
let mut acks = 0;
for i in 0..acked_length.len() {
if acked_length[i] >= length {
acks += 1;
}
}
acks
}