What's behind Automerge? (Part II)
Storage
From operations to changes
Before applying operations received from other actors, it’s necessary to ensure that they are causally ready. This rule applies to most Operation-based CRDTs 1.
We can use vector clocks to ensure that all operations are causally applied, but it is not Byzantine fault tolerant. Another way is to use Hash DAG 2. By recording the dependencies of each operation, other actors can determine if it is causally ready when they receive it by checking if its dependencies exist in the current OpSet.
As the number of operations increases, maintaining the Hash DAG can become cumbersome. In Automerge, we take a different approach by using change. A change is a combination of operations, as you have seen before:
let mut doc = Automerge::new();
let mut tx = doc.transaction();
tx.put(ROOT, "name", "Alice")?;
tx.put(ROOT, "age", "21")?;
tx.commit();
In this example, put(root, "name", "Alice") and put(root, "age", 21) belong to the same transaction. When committing, we combine all operations to create a change. A change is the minimum unit of applying, which implies that all the operations in a change are either fully applied or not applied at all.
By doing so, we can manage the dependencies between changes rather than dependencies between operations. In Automerge, we use a struct ChangeGraph to maintain this Hash DAG:
pub(crate) struct ChangeGraph {
nodes: Vec<ChangeNode>,
edges: Vec<Edge>,
hashes: Vec<ChangeHash>,
nodes_by_hash: BTreeMap<ChangeHash, NodeIdx>,
}
For example, a change graph created by actors may look like this:
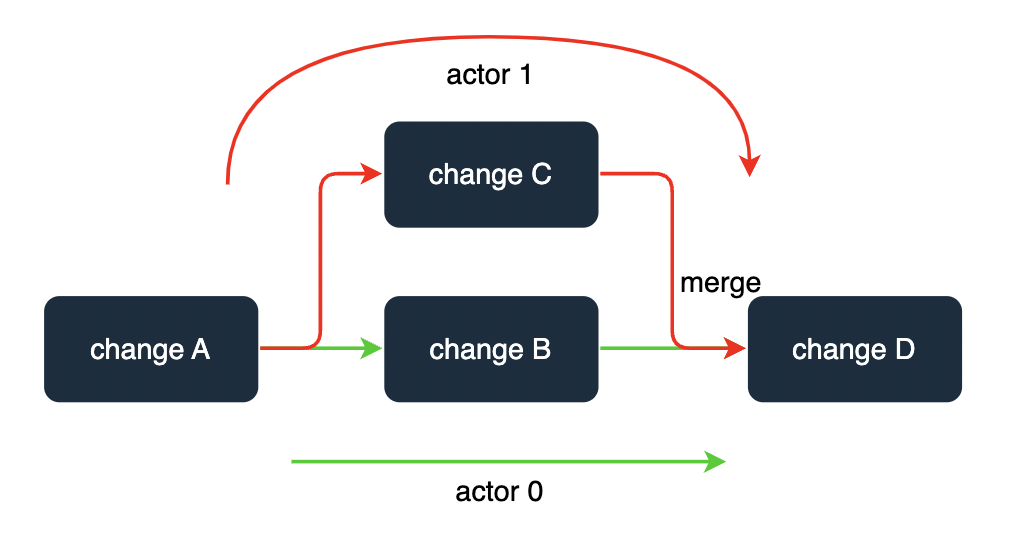
Before applying change D, it is necessary to ensure that changes B and C have already been applied, as illustrated in the diagram.
Moreover, using changes not only avoids the need to maintain a large number of dependencies but also enables us to compress operations efficiently. These operations can be viewed as a table, where each operation represents a row in the table. By utilizing columnar encoding, we can encode this table and greatly reduce the space required to store it.
Moving forward, we will explore the process of encoding these operations into a compact format. Before proceeding, you have the option to familiarize yourself with the specification of Automerge binary encoding. However, it is also possible to skip the specification for now, as we will provide essential information on encoding a basic change in the following sections. In case you encounter any difficulties, you can refer back to the specification to resolve them.
Change encoding
In order to exchange changes between actors, we need to encode them. If we serialize all operations directly in sequence, it would take up a lot of space. This is because we use a large amount of metadata to describe elements in Automerge. For example, when working with text, we use UTF-8 to describe a character, but we need to use hundreds of bytes to describe metadata related to it, such as OpId, objId, and so on.
Therefore, to compress operations during the encoding of changes, we utilize columnar encoding. To give you an intuitive impression, we provide an example:
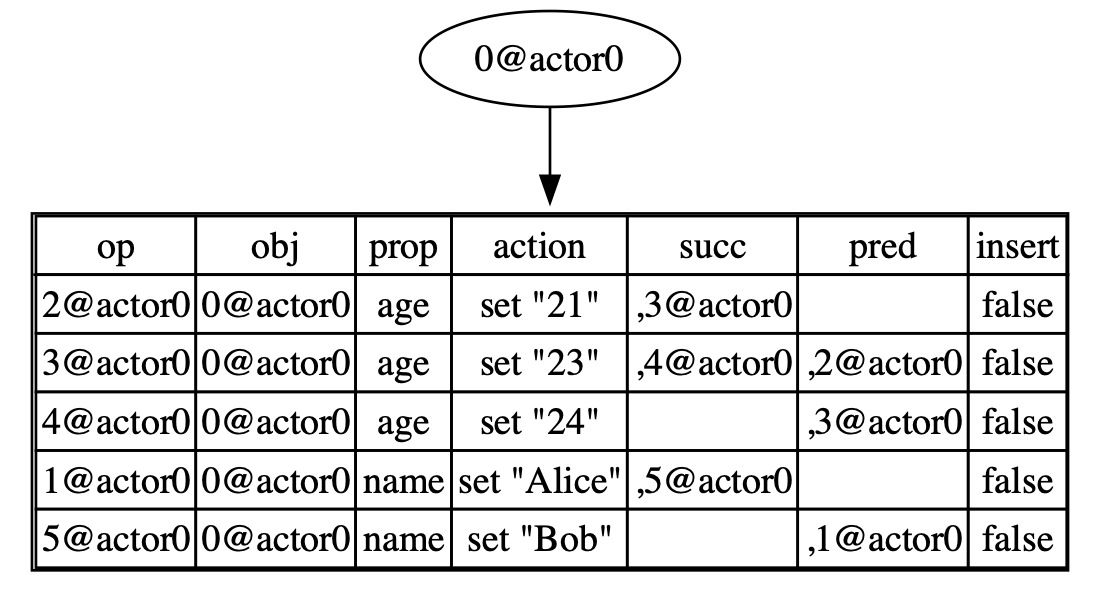
When we perform columnar encoding on a table consisting of such operations, we can use [5, 0@actor0] to encode the obj column, which represents 5 occurrences of 0@actor0.
In the next section, we will describe how to perform columnar encoding on a table of operations specifically.
Encoding
- Run Length Encoding (RLE)
Run length encoded column consists of multiple (length, value) pairs. For example, [5, 5, 5, 3, 3] can be encoded as [(3, 5), (2, 3)].
To elaborate further, assuming the length is k, we follow these rules:
- If k > 0, it means that the value is repeated
ktimes. - If k = 0, it means that
nullis repeatedvaluetimes. - If k < 0, it means that the next
|k|values are not repeated. In other words, there is no compression in this case.
In Automerge, we use RLE on the following columns:
| Column Name | Description | Format |
|---|---|---|
| object counter | counter of the object ID each operation targets | RLE of uLEB |
| key counter | counter of the operation ID of the key of each operation | RLE of uLEB |
| key string | The string key each operation targets | RLE of UTF8 Strings |
| action | The Action of each operation | RLE of uLEB |
uLEB (unsigned Little-Endian Base) is a variable-length encoding for unsigned integer.
- Delta encoding
When dealing with certain columns, RLE alone may not be efficient enough. For instance, if we have a column [1, 2, 3, 5, 7], we cannot use RLE to compress it. One solution is to use delta encoding first, encoding it as [+1, +1, +1, +2, +2], and then use RLE to encode it as [(3, +1), (2, +2)].
In Automerge, we use delta encoding on the following columns:
| Column Name | Description | Format |
|---|---|---|
| counter | The counter of each operations ID | Delta encoding of uLEB |
- Boolean encoding
For the boolean type, we can make it more compact. The column contains sequences of uLEB integers that represent the lengths of alternating sequences of false/true. The initial value of the column is always false. For example, [false, true, true, true, false, false] would be encoded as [1, 3, 2].
In Automerge, we use boolean encoding on the following columns:
| Column Name | Description |
|---|---|
| insert | Whether or not this is an insert operation |
- Actor encoding
Automerge utilizes a 16-byte random number to denote an actor ID. Due to its high byte count and small cardinality, it can be more efficiently managed by first saving it in a index -> actor ID map and then storing only the index. To store the index, RLE of uLEB is used.
In Automerge, we use actor encoding on the following columns:
| Column Name | Description |
|---|---|
| object actor ID | actor index of object ID each operation targets |
| key actor ID | actor of the operation ID of the key of each operation |
| actor ID | The actor of each operations ID |
- Group encoding
In Automerge, some columns can contain multiple values per operation. To handle this, group encoding is used. It consists of two columns:
-
The first column represents the number of elements in the row and is encoded using RLE of uLEB. For instance,
[[1, 2], [1, 2, 3]]would be encoded as[2, 3]. -
The second column contains the actual stored values and is encoded as a flat list. For example,
[[1, 2], [1, 2, 3]]would be encoded as[1, 2, 1, 2, 3]. Additionally, group encoding can be combined with other encodings such as delta encoding, which would encode[1, 2, 1, 2, 3]as[+1, +1, -1, +1, +1].
In Automerge, we use group encoding on the following columns:
| Column Name | Description | Format |
|---|---|---|
| predecessor actor IDs | The actor ID of each predecessor’s operation ID | Grouped Actor encoding |
| predecessor counters | The counter of each predecessor’s operation ID | Grouped Delta encoding |
| successor actor IDs | The actor ID of each successor’s operation ID | Grouped Actor encoding |
| successor counters | The counter of each successor’s operation ID | Grouped Delta encoding |
- Value encoding
For primitive values, we need to indicate their type and length. Therefore, we divide the value encoding into two columns:
- The first column stores the value metadata, which looks like this:

The types represented by numbers 0 to 9 currently include: null, false, true, unsigned integer, signed integer, IEEE754 float, UTF8 string, bytes, counter, and timestamp.
- The second column stores the actual bytes.
In Automerge, we use value encoding on the following columns:
| Column Name | Description |
|---|---|
| value | The value of this operation |
Change metadata
In addition to including all the operations, a change also needs to include some of its own metadata. In memory, we represent a change as follows:
pub(crate) struct Change<'a, O: OpReadState> {
/// The raw bytes of the entire chunk containing this change, including the header.
bytes: Cow<'a, [u8]>,
header: Header,
dependencies: Vec<ChangeHash>,
actor: ActorId,
other_actors: Vec<ActorId>,
seq: u64,
start_op: NonZeroU64,
timestamp: i64,
message: Option<String>,
ops_meta: ChangeOpsColumns,
/// The range in `Self::bytes` where the ops column data is
ops_data: Range<usize>,
extra_bytes: Range<usize>,
_phantom: PhantomData<O>,
}
Here’s a brief explanation of what these metadata mean:
headercontains information about the change chunk, such as the chunk type and checksum.dependenciesare the hash values of the changes on which this change depends.actorrefers to the actor ID that constructed the current change.other_actorsincludes all the actors that appear later. It is actually theindex -> ActorIDmap.seqrefers to the number assigned to the current change within the actor. Note that it is not the Lamport clock.<actor ID, seq>uniquely identifies a change.- The
start_oprefers to the operation ID at the beginning of the current change. timestampandmessageare specified duringcommit.ops_metadescribes the metadata of the operation table, such as which columns are included.ops_dataincludes the actual data of the operation table.
Example
We use an example to illustrate how a change is encoded. Suppose we have the following code:
let mut doc = Automerge::new();
let mut tx = doc.transaction();
tx.put(ROOT, "name", "Alice")?;
tx.put(ROOT, "age", 21)?;
tx.commit();
It will be encoded to the byte sequence like this:
856f4a83264ba5060140001003ebab6d29df47f39c5ea7d4cd9d6e03010100000006150a340142025604570970027e046e616d65036167650202017e8601144c69616e6772756e150200
856f4a83fc117446013c0010ba92a37960334606aa47606579716f20010100000006150a340142025603570670027e046e616d65036167650202017e5614416c696365150200
We can deconstruct it into different parts:
0x856f4a83 // magic
0xfc117446 // checksum
0x01 // chuck type
0x3c // chunk length
0x00 // dependencies
0x10 // actor length
0xba92a37960334606aa47606579716f20 //actor
0x01 // sequence number
0x01 // start op
0x00 // time
0x00 // message length
0x00 // other actors
0x06150a34014202560357067002 // operation column metadata
0x7e046e616d65036167650202017e5614416c696365150200 // operation columns
Change metadata
- magic
The magic is defined as [0x85, 0x6f, 0x4a, 0x83].
- checksum
The checksum is calculated by computing the SHA256 of all subsequent parts and taking the first 4 bytes.
SHA256(013c0010ba92a37960334606aa47606579716f20010100000006150a340142025603570670027e046e616d65036167650202017e5614416c696365150200) = fc117446c2701317ab462d610d17981fc12ac4cae6e242515d401db831a6e6d4
- chunk type
The chunk type of a change is always equal to 0x01.
- chunk length
The chunk length indicates how many bytes follow and is of type uLEB. In this case, 0x3c is equal to 0b00111100, so the length of the following bytes is 0b011 1100, which is 60 bytes.
- dependencies
The format for dependencies is as follows: first, there is a uLEB that indicates how many dependencies there are. In this case, the value is 0, which means there are no dependencies
- actor length
This is in uLEB format, which indicates the length of the actor in bytes. 0x10 represents 16 bytes, so the next 16 bytes represent the actor.
- actor
0xba92a37960334606aa47606579716f20 is the actor ID.
- sequence number
In uLEB format, it represents the seq of the change. Here, 0x01 = 1, so the sequence number is 1.
- start op
In uLEB format, 0x01 = 1, so the start op is 1.
- time
In uLEB format, the time is empty by default, so here 0x00 = 0.
- message length
In uLEB format, the message is empty by default, so here 0x00 = 0.
- other actors
It uses a uLEB to indicate how many actors there are. Here, since we have no other actors, 0x00 = 0.
Operation column metadata
Following the uLEB 0x06 = 6 indicating the number of columns, there are 6 pairs of <Column Specification, Column Length>:
| Column Specification | Column Length |
|---|---|
| 0x15 = 21, key string | 0x0a |
| 0x34 = 52, insert | 0x01 |
| 0x42 = 66, action | 0x02 |
| 0x56 = 86, value metadata | 0x03 |
| 0x57 = 87, value | 0x06 |
| 0x70 = 112, predecessor group | 0x02 |
The sum of 0x0a + 0x01 + 0x02 + 0x03 + 0x06 + 0x02 is 24, so the next 24 bytes are operation columns.
Operation columns
- key string:
7e046e616d650361676
In Automerge, key string is encoded using Run Length Encoding (RLE).
Here, the length is 0x7e = 0b01111110, which in two’s complement is -2, indicating that there is no compression.
The value part is 046e616d6503616765, which consists of several <uLEB byte count + actual bytes> pairs.
- The first byte count is
0x04 = 4, indicating that the next 4 bytes is the first string, which is0x6e616d65, resulting in “name” when decoded using UTF-8. - The second byte count is
0x03 = 3, indicating that the next 3 bytes is the second string, which is0x616765, resulting in “age” when decoded using UTF-8.
Therefore, we end up with the key strings ["name", "age"].
- insert
02
The type of insert is boolean, which is encoded using Boolean Encoding.
Therefore, [0x02] represents [false, false].
- action
0201
RLE is used for the action column. Here, 0x02 = 2, indicating that the value is repeated twice.
The value part is 0x01. Repeating it twice gives us [0x01, 0x01].
According to the Automerge specification, 0x01 as the action value means “set”. Therefore, the action column is [set, set].
- value metadata
7e5614
The value metadata is encoded using the Value Encoding.
0x56 = 0101 0110 can be interpreted as 0b 101 0110, which means the first type is 0b0110 (String), and the length is 0b101 = 5 bytes.
The following 0x14 = 0b0001 0100, indicates that the second type is 0b100 (Signed Integer), and the length is 0b1 = 1 byte.
So the entire value metadata column can be interpreted as [<String, 8>, <Signed Integer, 1>].
- value
416c69636515
0x416c696365 is converted to the UTF-8 string “Alice”. And 0x15 = 21.
Therefore, the value column can be interpreted as ["Alice", 21].
- predecessor group
0200
The first column of the predecessor group is encoded using RLE, which is equivalent to [0x00, 0x00] here. This means that there are no predecessors for these two operations. Therefore, the predecessor group is interpreted as [[], []].
Document encoding
A new actor may start joining the synchronization of a document without any changes. It is inefficient to transmit each change individually. In this scenario, we can serialize and transmit the entire document. Furthermore, serialization of the document is also useful when we intend to persist it in disk storage.
The document is essentially a set of changes. However, when we encode it, we divide it into two distinct tables: the change table and the operation table. The change table stores the metadata related to the changes, whereas the operation table stores all the operations of the document.
The reason why we separate the change table and the operation table is that doing so allows us to better utilize columnar encoding, which results in higher compression rates.
pub(crate) struct Document<'a> {
bytes: Cow<'a, [u8]>,
#[allow(dead_code)]
compressed_bytes: Option<Cow<'a, [u8]>>,
header: Header,
actors: Vec<ActorId>,
heads: Vec<ChangeHash>,
op_metadata: DocOpColumns,
op_bytes: Range<usize>,
change_metadata: DocChangeColumns,
change_bytes: Range<usize>,
#[allow(dead_code)]
head_indices: Vec<u64>,
}
Example
We use an example to illustrate how a document is encoded. Suppose we have the following code:
let mut doc = Automerge::new();
let mut tx1 = doc.transaction();
tx1.put(ROOT, "name", "Bob")?;
tx1.put(ROOT, "age", 21)?;
tx1.commit();
let mut tx2 = doc.transaction();
tx2.put(ROOT, "gender", "male")?;
tx2.commit();
doc.save();
It will be encoded to the byte sequence like this:
856f4a83e7a6f50e009301011013336ec1ed354befa60b3e3f05346028012f2f0a65b40461263a496749d8bb0b0746c234cbddb092e11473861242638a0c07010203021303230240034302560208151121022304340142025605570d800102020002017e020102007e00017f0002077d036167650667656e646572046e616d6503007d02017e0303017d14468601156d616c654c69616e6772756e030001
856f4a834afcae9c008d01011015cb7623f0314fc09773daafcf4138d7016cdffc539c7e02a93ab4f9762fc4466b90fc4134c6662382d067f02d9e9418bf070102030213032302400343025602081511210223043401420256045708800102020002017e020102007e00017f0002077d036167650667656e646572046e616d6503007d02017e0303017d144636156d616c65426f62030001
We can deconstruct it into different parts:
0x856f4a83 // magic
0x4afcae9c // checksum
0x00 // chunk type
0x8d01 // chunk length
0x011015cb7623f0314fc09773daafcf4138d7 // actors
0x016cdffc539c7e02a93ab4f9762fc4466b90fc4134c6662382d067f02d9e9418bf // heads
0x070102030213032302400343025602 // change column metadata
0x081511210223043401420256045708800102 // operation column metadata
0x020002017e020102007e00017f000207 // change column
0x7d036167650667656e646572046e616d6503007d02017e0303017d144636156d616c65426f620300 // operation columns
0x01 // heads index
As most of the fields are similar to change encoding, we will not explain them here. Instead, we will only illustrate the change column metadata , operation column metadata, change column and operation column .
change columns metadata
0x070102030213032302400343025602
Following the uLEB 0x07 = 7 indicating the number of columns, there are 7 pairs of <Column Specification, Column Length>:
| Column Specification | Column Length |
|---|---|
| 0x01 = 1, actor | 0x02 |
| 0x03 = 3, sequence number | 0x02 |
| 0x13 = 19, maxop | 0x03 |
| 0x23 = 35, time | 0x02 |
| 0x40 = 64, dependencies group | 0x03 |
| 0x43 = 67, dependencies index | 0x02 |
| 0x56 = 86, extra metadata | 0x02 |
0x02 + 0x02 + 0x03 + 0x02 + 0x03 + 0x02 + 0x02 = 16 bytes.
operation columns metadata
0x081511210223043401420256045708800102
Following the uLEB 0x08 = 8 indicating the number of columns, there are 8 pairs of <Column Specification, Column Length>:
| Column Specification | Column Length |
|---|---|
| 0x15 = 21, key string | 0x11 |
| 0x21 = 33, actor ID | 0x02 |
| 0x23 = 35, counter | 0x04 |
| 0x34 = 52, insert | 0x01 |
| 0x42 = 66, action | 0x02 |
| 0x56 = 86, value metadata | 0x04 |
| 0x57 = 87, value | 0x08 |
| 0x8001 = 128, successor group | 0x02 |
0x11 + 0x02 + 0x04 + 0x01 + 0x02 + 0x04 + 0x08 + 0x02 = 40 bytes
change columns
0x020002017e020102007e00017f000207
- actor
0200
The actor column uses RLE. First, the length is 0x02, indicating that the value is repeated twice. Then, the value is 0x00, indicating that the actor column is [0x00, 0x00].
In this case, 0x00 refers to the first actor in the actors list, which is 0x011015cb7623f0314fc09773daafcf4138d7.
- sequence number
0201
The sequence number uses RLE. Here, the length is 0x02, indicating that the value is repeated twice. The value is 0x01, which means that the actual value is [0x01, 0x01].
The value part of the sequence number uses delta encoding. Therefore, [0x01, 0x01] is equivalent to [1, 2].
- maxop
7e0201
maxop uses RLE. Here, the length is 0x7e, which is equivalent to -2 in 2’s comlement number format. The value is 0x0201, which mean the actual value is [0x02, 0x01].
Since it is delta encoded, this value represents [0x02, 0x03].
- time
0200
The length of the RLE is 0x02, indicating that 0x00 is repeated twice. Therefore, time is not recorded here.
- dependencies group
7e0001
Dependencies group can be interpreted as [0x00, 0x01]. As a result, the first change has no dependencies, while the second change has one dependency.
- dependencies index
7f00
0x7f is equivalent to -1 in RLE encoding, indicating that the value is not repeated. The following value is 0x00. The dependencies index for the two changes is therefore: [[], [0x00]].
operation columns
0x7d036167650667656e646572046e616d6503007d02017e0303017d144636156d616c65426f620300
- key string
7d036167650667656e646572046e616d65
0x7d is -3 in 2’s complement, indicating that the value is not repeated. The value part is as follows:
- 03 represents the length of the first value, so the next three bytes are
0x616765, which corresponds to “age”. - 06 represents the length of the second value, so the next six bytes are
0x67656e646572, which corresponds to “gender”. - 04 represents the length of the third value, so the next four bytes are
0xe616d65, which corresponds to “name”.
Therefore, the final result is [“age”, “gender”, “name”].
- actor ID
0300
Here is RLE encoded, so 0x03 represents repeating 3 times, and the value is 0x00. Therefore, the final decoding result is [0x00, 0x00, 0x00].
- counter
7d02017e
The value 0x7d indicates that there is no repetition, and the sequence of values 0x02 0x01 0x7e represents the delta encoding [+2, +1, -2]. The resulting decoded sequence is [2, 3, 1].
- insert
03
0x03 represents 3 times false, which is [false, false, false].
- action
0301
0301 represents three times 0x01, which means [0x01, 0x01, 0x01].
According to the Automerge specification, 0x01 as the action value means “set”. Therefore, the action column is [set, set, set].
- value metadata
7d144636
0x7d = -3, which means there is no compression used.
Next is the value part, which consists of several 64-bit uLEBs:
14= 0001 0100, which means type = 0b100 (Signed integer), length = 0b1 = 1 byte.46= 0100 0110, which means type = 0b110 (String), length = 0b100 = 4 bytes.36= 0011 0110, which means type = 0b110 (String), length = 0b11 = 3 bytes.
Therefore, the entire value metadata column can be interpreted as [<Signed Integer, 1>, <String, 4>, <String, 3>].
- value
156d616c65426f62
- Signed Integer,
0x15= 21 - String,
0x6d616c65= “male” - String,
0x426f62= “Bob”
Therefore, the entire value column can be interpreted as [21, “male”, “Bob”].
- successor group
0300
0x0300 means three times 0x00, which is equivalent to [0x00, 0x00, 0x00].
So there is no successor for all the operations. Hence the operation group can be interpreted as [[], [], []].
Reference
[1]. M. Shapiro, N. Preguiça, C. Baquero, and M. Zawirski, “Conflict-free replicated data types,” Lecture Notes in Computer Science, pp. 386–400, 2011. doi:10.1007/978-3-642-24550-3_29
[2]. Kleppmann M, Howard H. Byzantine eventual consistency and the fundamental limits of peer-to-peer databases[J]. arXiv preprint arXiv:2012.00472, 2020.